GPU 通信相关
GPU 通信相关
1. 硬件知识
1.1 网卡
测试的H20网卡型号:
[root@ys-h20-7k5h6y36-0000 ~]# lspci | grep -i eth
0000:2c:00.0 Ethernet controller: Mellanox Technologies MT43244 BlueField-3 integrated ConnectX-7 network controller (rev 01)
0000:2c:00.1 Ethernet controller: Red Hat, Inc. Virtio network device (rev 01)
0000:2d:00.0 Ethernet controller: Red Hat, Inc. Virtio network device (rev 01)
0000:7f:00.0 Ethernet controller: Mellanox Technologies MT43244 BlueField-3 integrated ConnectX-7 network controller (rev 01)
0000:7f:00.1 Ethernet controller: Mellanox Technologies MT43244 BlueField-3 integrated ConnectX-7 network controller (rev 01)
0000:c7:00.0 Ethernet controller: Mellanox Technologies MT43244 BlueField-3 integrated ConnectX-7 network controller (rev 01)
0000:c7:00.1 Ethernet controller: Mellanox Technologies MT43244 BlueField-3 integrated ConnectX-7 network controller (rev 01)
0001:08:00.0 Ethernet controller: Mellanox Technologies MT43244 BlueField-3 integrated ConnectX-7 network controller (rev 01)
0001:08:00.1 Ethernet controller: Mellanox Technologies MT43244 BlueField-3 integrated ConnectX-7 network controller (rev 01)
0001:a2:00.0 Ethernet controller: Mellanox Technologies MT43244 BlueField-3 integrated ConnectX-7 network controller (rev 01)
0001:a2:00.1 Ethernet controller: Mellanox Technologies MT43244 BlueField-3 integrated ConnectX-7 network controller (rev 01)
可以看到使用的BlueField-3 integrated ConnectX-7网卡。常见的网卡性能数据:
| GPU型号 | 常见搭配网卡 | 网络速率(bps) | 发布时间 |
|---|---|---|---|
| V100 / T4 | ConnectX-4/5 | 25G / 50G / 100G | 2017–2018 |
| RTX 3090 | ConnectX-5 | 100G | 2020 |
| RTX 4090 | ConnectX-5/6 | 100G / 200G | 2022 |
| L40S / 6000 Ada | ConnectX-6 | 200G | 2023 |
| H20 | ConnectX-6/7 | 200G / 400G | 2023 |
| A100 | ConnectX-6 | 200G | 2020 |
| H100 | ConnectX-7 | 400G | 2022 |
| H200 | ConnectX-7/8 | 400G / 800G | 2024 |
| B200 | ConnectX-8 | 800G | 2024–2025 |
| Grace Hopper GH200 | ConnectX-7 | 400G | 2023 |
在 InfiniBand / RDMA 架构里,把网卡(NIC)抽象为HCA(Host Channel Adapter),HCA可以给主机提供RDMA verbs 接口。
- InfiniBand:一种物理层 + 链路层 + 网络层 + 传输层的完整网络协议(需要 InfiniBand 交换机和线缆)
- verbs:一组用户态 API,类似于 Linux Socket API 定义了 TCP/UDP 通信方式,verbs API 定义了 RDMA 通信方式,API 的实现由 libibverbs 提供,底层由网卡驱动 (mlx5 内核模块) 处理。
- libibverbs: Linux下的一个 用户态库,提供应用程序访问HCA的接口,就像 libc 实现了 open()/read()/write() 这些系统调用一样,libibverbs 实现了 ibv_post_send()/ibv_post_recv() 这些 verbs 调用。
查看一下HCA的信息:
[root@ys-h20-7k5h6y36-0000 bin]# ibv_devinfo | egrep "hca_id|port:"
hca_id: mlx5_bond_0
transport: InfiniBand (0)
port: 1
hca_id: mlx5_bond_1
transport: InfiniBand (0)
port: 1
hca_id: mlx5_bond_2
transport: InfiniBand (0)
port: 1
hca_id: mlx5_bond_3
transport: InfiniBand (0)
port: 1
可以看到有4个HCA设备,这些设备可以通过InfiniBand verbs API调用。
查看一下网口的信息:
[root@ys-h20-7k5h6y36-0000 draw]# ip link show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
3: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP mode DEFAULT group default qlen 1000
link/ether 00:16:3e:04:65:f9 brd ff:ff:ff:ff:ff:ff
5: reth0: <BROADCAST,MULTICAST,SLAVE,UP,LOWER_UP> mtu 9000 qdisc mq master bond0 state UP mode DEFAULT group default qlen 1000
link/ether 00:25:9d:59:10:bf brd ff:ff:ff:ff:ff:ff
6: reth1: <BROADCAST,MULTICAST,SLAVE,UP,LOWER_UP> mtu 9000 qdisc mq master bond0 state UP mode DEFAULT group default qlen 1000
link/ether 00:25:9d:59:10:bf brd ff:ff:ff:ff:ff:ff
7: reth2: <BROADCAST,MULTICAST,SLAVE,UP,LOWER_UP> mtu 9000 qdisc mq master bond1 state UP mode DEFAULT group default qlen 1000
link/ether 00:25:9d:3a:d3:58 brd ff:ff:ff:ff:ff:ff
8: reth3: <BROADCAST,MULTICAST,SLAVE,UP,LOWER_UP> mtu 9000 qdisc mq master bond1 state UP mode DEFAULT group default qlen 1000
link/ether 00:25:9d:3a:d3:58 brd ff:ff:ff:ff:ff:ff
9: reth4: <BROADCAST,MULTICAST,SLAVE,UP,LOWER_UP> mtu 9000 qdisc mq master bond2 state UP mode DEFAULT group default qlen 1000
link/ether 00:25:9d:10:79:b3 brd ff:ff:ff:ff:ff:ff
10: reth5: <BROADCAST,MULTICAST,SLAVE,UP,LOWER_UP> mtu 9000 qdisc mq master bond2 state UP mode DEFAULT group default qlen 1000
link/ether 00:25:9d:10:79:b3 brd ff:ff:ff:ff:ff:ff
11: reth6: <BROADCAST,MULTICAST,SLAVE,UP,LOWER_UP> mtu 9000 qdisc mq master bond3 state UP mode DEFAULT group default qlen 1000
link/ether 00:25:9d:4f:2a:01 brd ff:ff:ff:ff:ff:ff
12: reth7: <BROADCAST,MULTICAST,SLAVE,UP,LOWER_UP> mtu 9000 qdisc mq master bond3 state UP mode DEFAULT group default qlen 1000
link/ether 00:25:9d:4f:2a:01 brd ff:ff:ff:ff:ff:ff
13: bond0: <BROADCAST,MULTICAST,MASTER,UP,LOWER_UP> mtu 9000 qdisc noqueue state UP mode DEFAULT group default qlen 1000
link/ether 00:25:9d:59:10:bf brd ff:ff:ff:ff:ff:ff
14: bond1: <BROADCAST,MULTICAST,MASTER,UP,LOWER_UP> mtu 9000 qdisc noqueue state UP mode DEFAULT group default qlen 1000
link/ether 00:25:9d:3a:d3:58 brd ff:ff:ff:ff:ff:ff
15: bond2: <BROADCAST,MULTICAST,MASTER,UP,LOWER_UP> mtu 9000 qdisc noqueue state UP mode DEFAULT group default qlen 1000
link/ether 00:25:9d:10:79:b3 brd ff:ff:ff:ff:ff:ff
16: bond3: <BROADCAST,MULTICAST,MASTER,UP,LOWER_UP> mtu 9000 qdisc noqueue state UP mode DEFAULT group default qlen 1000
link/ether 00:25:9d:4f:2a:01 brd ff:ff:ff:ff:ff:ff
17: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default
link/ether 02:42:3c:24:24:2b brd ff:ff:ff:ff:ff:ff
19: vethd5122f5@if18: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP mode DEFAULT group default
link/ether 3e:ad:00:13:84:8d brd ff:ff:ff:ff:ff:ff link-netnsid 0
可以看到有lo, eth0, reth0, reth1, reth2, reth3, reth4, reth5, reth6, reth7, bond0, bond1, bond2, bond3这些网口。
lo表示本地环回网口,eth0表示物理网口,reth 表示 底层物理网口(Real Ethernet),bond 表示 绑定网口(Bonding)。
看一下HCA和网口的关系:
[root@ys-h20-7k5h6y36-0000 bin]# ibdev2netdev
mlx5_bond_0 port 1 ==> bond0 (Up)
mlx5_bond_1 port 1 ==> bond1 (Up)
mlx5_bond_2 port 1 ==> bond2 (Up)
mlx5_bond_3 port 1 ==> bond3 (Up)
mlx5_bond_0绑定了bond0,mlx5_bond_1绑定了bond1,mlx5_bond_2绑定了bond2,mlx5_bond_3绑定了bond3。
看一下bond0的信息:
[root@ys-h20-7k5h6y36-0000 draw]# cat /proc/net/bonding/bond0
Ethernet Channel Bonding Driver: v3.7.1.9
Bonding Mode: IEEE 802.3ad Dynamic link aggregation
Transmit Hash Policy: layer3+4 (1)
MII Status: up
MII Polling Interval (ms): 100
Up Delay (ms): 0
Down Delay (ms): 0
Peer Notification Delay (ms): 0
802.3ad info
LACP rate: slow
Min links: 0
Aggregator selection policy (ad_select): stable
System priority: 65535
System MAC address: 00:25:9d:59:10:bf
Active Aggregator Info:
Aggregator ID: 1
Number of ports: 2
Actor Key: 65503
Partner Key: 190
Partner Mac Address: 00:00:5e:00:01:01
Slave Interface: reth0
MII Status: up
Speed: 200000 Mbps
Duplex: full
Link Failure Count: 0
Permanent HW addr: 5c:25:73:f7:b1:68
Slave queue ID: 0
Aggregator ID: 1
Actor Churn State: none
Partner Churn State: none
Actor Churned Count: 0
Partner Churned Count: 0
details actor lacp pdu:
system priority: 65535
system mac address: 00:25:9d:59:10:bf
port key: 65503
port priority: 255
port number: 1
port state: 61
details partner lacp pdu:
system priority: 32768
system mac address: 00:00:5e:00:01:01
oper key: 190
port priority: 255
port number: 95
port state: 61
Slave Interface: reth1
MII Status: up
Speed: 200000 Mbps
Duplex: full
Link Failure Count: 0
Permanent HW addr: 5c:25:73:f7:b1:69
Slave queue ID: 0
Aggregator ID: 1
Actor Churn State: none
Partner Churn State: none
Actor Churned Count: 0
Partner Churned Count: 0
details actor lacp pdu:
system priority: 65535
system mac address: 00:25:9d:59:10:bf
port key: 65503
port priority: 255
port number: 2
port state: 61
details partner lacp pdu:
system priority: 32768
system mac address: 00:00:5e:00:01:01
oper key: 190
port priority: 255
port number: 395
port state: 61
可以看到bond0聚合了reth0和reth1两个网口,每个物理网口的带宽为200Gbps。注意单个 TCP/UDP 流量 不会跨多条物理链路,它会固定走其中一条,bond0单个连接(单流)最大速率 = 200 Gb/s,多个连接(多流)并发时,理论总吞吐 ≈ 200 + 200 = 400 Gb/s。
但是GPUDirect RDMA 默认不会走 Linux bonding 哈希规则,它有自己的一套 多链路聚合机制:
- InfiniBand 模式下,可以用 多链路带宽聚合 (Link Aggregation / Multipath),自动把多条物理 lane 当成一个逻辑大口。
- lane:物理链路,每个物理链路可以承载一个 QP(Queue Pair)。
- RoCE 下,可以用 ECMP 或 LAG,不同 QP(Queue Pair)可以分布到不同链路。
- QP(Queue Pair):RDMA 通信的队列对,每个 QP 可以独立配置,包括发送队列和接收队列。
- RoCE(RDMA over Converged Ethernet):不是一个完整的栈,而是 把 RDMA verbs 放到以太网上承载,底层还是以太网 (Ethernet) + IP 路由。
- RoCE没有 IB 的 lane 聚合机制,取而代之的是:
- ECMP(Equal Cost Multi-Path):等价多路径路由,在交换机层面,通过哈希算法将QP均匀分配到多条路径上。
- LAG(Link Aggregation Group):链路聚合组,在 网卡侧(或交换机)将多条物理链路捆绑成一个逻辑链路,提高带宽和可靠性。
- 如果一个 QP 流量特别大,使用RoCE可能只跑在一条链路上,不能像 IB 那样天然合并。所以在RoCE上想要打满带宽,需要多 QP 并行,配合 LAG/ECMP 才能分摊流量。
再来看一下mlx5_bond_0的具体信息:
[root@ys-h20-7k5h6y36-0000 ~]# ibv_devinfo -v
hca_id: mlx5_bond_0
transport: InfiniBand (0) # verbs 层接口类型,通常写 InfiniBand,即使底层是 RoCE。
...
max_qp: 131072 # 支持的最大 QP 数量
max_qp_wr: 32768 # 单个 QP 的最大 work requests 数量(队列深度)。
...
max_sge: 30 # 单次请求最大 scatter/gather entries(即一次发送可拼接多少段内存)
max_sge_rd: 30
max_cq: 16777216 # 最大完成队列数
max_cqe: 4194303 # 每个 CQ 的条目数(队列深度)
max_mr: 16777216 # 支持的单个 Memory Region 最大注册内存大小
...
atomic_cap: ATOMIC_HCA (1) # 网卡硬件支持 RDMA 原子操作(fetch-and-add, compare-and-swap)
...
rc_odp_caps:
SUPPORT_SEND
SUPPORT_RECV
SUPPORT_WRITE
SUPPORT_READ
SUPPORT_ATOMIC
SUPPORT_SRQ # 支持从 GPU/CPU 的 page-fault 触发数据加载
...
cq moderation caps:
max_cq_count: 65535
max_cq_period: 4095 us
maximum available device memory: 65536Bytes
num_comp_vectors: 63
port: 1
state: PORT_ACTIVE (4)
max_mtu: 4096 (5)
active_mtu: 4096 (5) # MTU = 4096 字节,RoCE 默认大帧。越大越利于减少头部开销
sm_lid: 0
port_lid: 0
port_lmc: 0x00
link_layer: Ethernet # 真正的链路层,这里是 Ethernet → 表明走 RoCE。
max_msg_sz: 0x40000000
port_cap_flags: 0x04010000
port_cap_flags2: 0x0000
max_vl_num: invalid value (0)
bad_pkey_cntr: 0x0
qkey_viol_cntr: 0x0
sm_sl: 0
pkey_tbl_len: 1
gid_tbl_len: 255
subnet_timeout: 0
init_type_reply: 0
active_width: 2X (16) # 表示用两条 lane 聚合成 100G(可能是 2 × 50G SerDes)
active_speed: 100.0 Gbps (128) # 单端口单向速率 100Gb/s,全双工
phys_state: LINK_UP (5)
GID[ 0]: fe80:0000:0000:0000:0225:9dff:fe59:10bf, RoCE v1
GID[ 1]: fe80::225:9dff:fe59:10bf, RoCE v2
GID[ 2]: 0000:0000:0000:0000:0000:ffff:c812:000e, RoCE v1
GID[ 3]: ::ffff:200.18.0.14, RoCE v2
- CQ moderation
- HCA 完成一个 Work Request (WR) → 会生成一个 CQE (Completion Queue Entry) 放入 CQ。默认情况下,每个 CQE 都会触发一次 中断/通知,应用就能及时知道某个 WR 完成了。如果有成千上万条 WR,很快就会产生中断风暴,CPU 消耗严重。
- 为了解决这个问题,引入了 CQ moderation:HCA 可以把多个 CQE 批量汇报,减少中断次数。
- max_cq_count: CQ moderation 一次最多可以累积多少条 CQE,再统一触发一次通知。
- max_cq_period: CQ moderation 最多能延迟多久才触发通知(就算 CQE 数没达到阈值)
- Memory Region (MR)
- RDMA中,网卡(HCA)可以 直接访问用户态内存(zero-copy),但前提是这块内存必须事先告诉网卡,保证网卡 DMA 时不会出错,这一步就是 注册 Memory Region (MR)。
- Memory Region (MR) = 一段用户态内存,已经注册到 HCA,并获得一个 lkey/rkey,只有注册后的 MR,才能被 RDMA verbs(send, write, read, atomic)使用。
- 注册MR流程:
- 应用调用 ibv_reg_mr() 把内存注册成 MR。
- HCA 驱动会 pin(固定)这段内存,防止它被换出。
- 驱动把虚拟地址和物理页帧映射传给 HCA。
- HCA 返回一个 lkey (local key) 和 rkey (remote key)。
- lkey:本地访问时使用(本地 QP 引用这块内存)。
- rkey:远端 RDMA 访问时使用(对方 QP 需要 rkey 才能写/读本地内存)。
- Scatter/Gather Entry(SGE)
- SGE描述的是一段 内存缓冲区(地址 + 长度 + lkey)。
- 在 RDMA 里,一个 Work Request (WR) 里可以包含多个 SGE → 组成一个 SG List (Scatter/Gather List)。
- 在实际应用中,数据可能并不是放在连续的内存里,而是分散在多个 buffer 中。
- 没有 SGE:要先把这些 buffer 拷贝到一个连续内存里再发。
- 有 SGE:可以直接把多个 buffer 的地址列出来(多个 SGE),网卡(HCA)会一次性 DMA 这些零散数据 → 零拷贝传输。
- ODP (On-Demand Paging)
- 在没有 ODP 的情况下,使用 RDMA 之前,你必须 提前注册一整段内存 (ibv_reg_mr),注册时,HCA 驱动会 pin(固定) 那些物理页,告诉 HCA 地址映射。
- ODP 允许 HCA 在 访问内存时,遇到页不在内存里(page-fault),再由内核/驱动去处理
- GPU 内存 ODP (GPUDirect ODP):HCA 发 DMA → 页还没映射到 GPU BAR/内存 → 触发 GPU page fault → CUDA driver/NVIDIA 内核模块建立映射 → HCA 再继续访问。
- (推理场景没必要,一次性注册好让所有显存都可以被网卡访问就好了)
这里还可以看到链路层(link_layer)走的以太网(Ethernet),所以实际上用的RoCE,而不是一整套InfiniBand。
1.2 硬件总线上的拓扑结构
通过命令:
[root@ys-h20-7k5h6y36-0000 draw]# lstopo --of png > topo.png
可以获取到硬件总线上的拓扑结构:
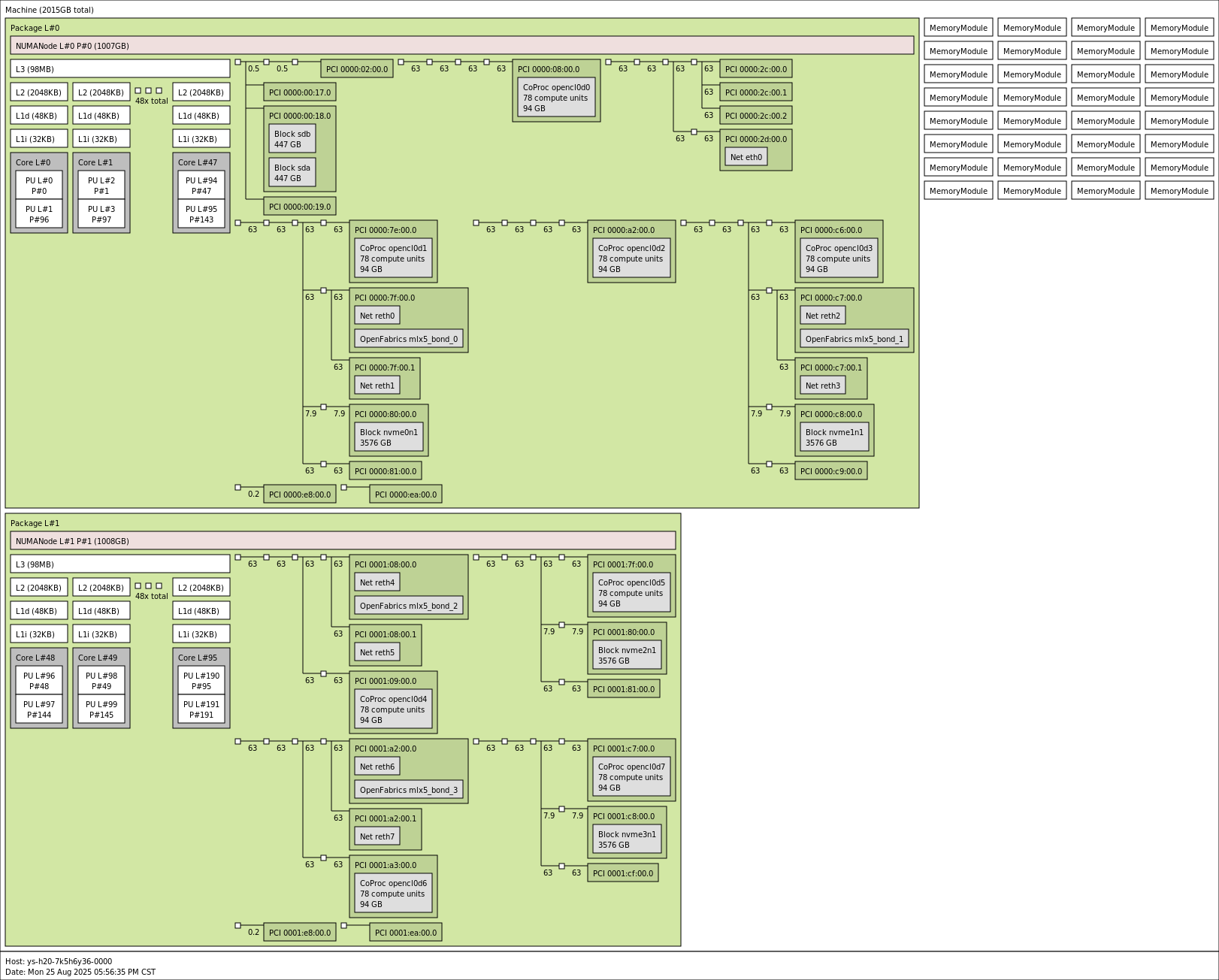
连线的数字代表链路带宽(GB/s),可以看到PCIe 64GB/s(双向)的理论值。
- NUMA(Non-Uniform Memory Access):非一致性内存访问。在多路 CPU(多个物理 CPU 插槽,或 Chiplet 设计)系统中,每个 CPU(Socket)有自己直连的内存。本地 CPU 访问“自己插槽的内存”速度快;访问“别的 CPU 插槽的内存”需要跨 QPI/UPI/Infinity Fabric 链接,延迟更高,带宽更低。
也可以通过nvidia-smi topo -m 查看:
[root@ys-h20-7k5h6y36-0000 draw]# nvidia-smi topo -m
GPU0 GPU1 GPU2 GPU3 GPU4 GPU5 GPU6 GPU7 NIC0 NIC1 NIC2 NIC3 CPU Affinity NUMA Affinity GPU NUMA ID
GPU0 X NV18 NV18 NV18 NV18 NV18 NV18 NV18 NODE NODE SYS SYS 0-47,96-143 0 N/A
GPU1 NV18 X NV18 NV18 NV18 NV18 NV18 NV18 PIX NODE SYS SYS 0-47,96-143 0 N/A
GPU2 NV18 NV18 X NV18 NV18 NV18 NV18 NV18 NODE NODE SYS SYS 0-47,96-143 0 N/A
GPU3 NV18 NV18 NV18 X NV18 NV18 NV18 NV18 NODE PIX SYS SYS 0-47,96-143 0 N/A
GPU4 NV18 NV18 NV18 NV18 X NV18 NV18 NV18 SYS SYS PIX NODE 48-95,144-191 1 N/A
GPU5 NV18 NV18 NV18 NV18 NV18 X NV18 NV18 SYS SYS NODE NODE 48-95,144-191 1 N/A
GPU6 NV18 NV18 NV18 NV18 NV18 NV18 X NV18 SYS SYS NODE PIX 48-95,144-191 1 N/A
GPU7 NV18 NV18 NV18 NV18 NV18 NV18 NV18 X SYS SYS NODE NODE 48-95,144-191 1 N/A
NIC0 NODE PIX NODE NODE SYS SYS SYS SYS X NODE SYS SYS
NIC1 NODE NODE NODE PIX SYS SYS SYS SYS NODE X SYS SYS
NIC2 SYS SYS SYS SYS PIX NODE NODE NODE SYS SYS X NODE
NIC3 SYS SYS SYS SYS NODE NODE PIX NODE SYS SYS NODE X
Legend:
X = Self
SYS = Connection traversing PCIe as well as the SMP interconnect between NUMA nodes (e.g., QPI/UPI)
NODE = Connection traversing PCIe as well as the interconnect between PCIe Host Bridges within a NUMA node
PHB = Connection traversing PCIe as well as a PCIe Host Bridge (typically the CPU)
PXB = Connection traversing multiple PCIe bridges (without traversing the PCIe Host Bridge)
PIX = Connection traversing at most a single PCIe bridge
NV# = Connection traversing a bonded set of # NVLinks
NIC Legend:
NIC0: mlx5_bond_0
NIC1: mlx5_bond_1
NIC2: mlx5_bond_2
NIC3: mlx5_bond_3
通过拓扑图可以看到:
- GPU0、1、2、3, NIC0、1在NUMA Node0上
- NIC0离GPU1最近,数据链路走单一的PCIe bridge,在nvidia-smi中显示为PIX
- NIC1离GPU3最近,数据链路走单一的PCIe bridge,在nvidia-smi中显示为PIX
- GPU0、2与NIC0、1的数据链路走不同的PCIe Host Bridge之间的连接,在nvidia-smi中显示为NODE
- GPU4、5、6、7,NIC2、3在NUMA Node1上
- NIC2离GPU4最近,数据链路走单一的PCIe bridge,在nvidia-smi中显示为PIX
- NIC3离GPU6最近,数据链路走单一的PCIe bridge,在nvidia-smi中显示为PIX
- GPU5、7与NIC2、3的数据链路走不同的PCIe Host Bridge,在nvidia-smi中显示为NODE
如果GPU要跨NUMA Node使用NIC,就要走跨 Socket 的 NUMA 互联,在nvidia-smi中显示为SYS。
传输速度:PIX > PXB > PHB > NODE > SYS
| 路径类型 | 说明 | Gen4 x16 理论带宽 | Gen4 x16 常见实测 | Gen5 x16 理论带宽 | Gen5 x16 常见实测 | 典型延迟 (µs) |
|---|---|---|---|---|---|---|
| PIX | 同一 PCIe switch 或最多 1 个 bridge | 31.5 GB/s | 26–30 GB/s | 63.0 GB/s | 48–58 GB/s | 1–2 |
| PXB | 多级 PCIe bridge/交换,不经过 Host Bridge | 31.5 GB/s | 24–28 GB/s | 63.0 GB/s | 45–55 GB/s | 1.5–2.5 |
| PHB | 穿过 PCIe Host Bridge (Root Complex) | 31.5 GB/s | 22–27 GB/s | 63.0 GB/s | 40–52 GB/s | 2–3 |
| NODE | 同 NUMA,不同 Host Bridge 互联 | 31.5 GB/s | 18–25 GB/s | 63.0 GB/s | 35–48 GB/s | 4–6 |
| SYS | 跨 NUMA,经 QPI/UPI/InfinityFabric | 31.5 GB/s | 12–22 GB/s | 63.0 GB/s | 25–40 GB/s | 8–15 |
可以通过perftest库测试不同路径的传输速度:
- perftest库安装:
git clone https://github.com/linux-rdma/perftest.git
cd perftest
./autogen.sh
./configure
make -j$(nproc)
make install
- perftest测试GPU-NIC带宽:
# 终端A(server)
ib_write_bw -d mlx5_bond_0 --use_cuda=4 -F -q 1 -n 1000 --report_gbits
# 终端B(client)
ib_write_bw -d mlx5_bond_0 --use_cuda=4 -F -q 1 -n 1000 --report_gbits <mlx5_bond_0_ip>
查看网卡ip:
[root@ys-h20-7k5h6y36-0000 perftest]# ip -br a
lo UNKNOWN 127.0.0.1/8 ::1/128
eth0 UP 172.19.77.153/20 fe80::216:3eff:fe04:65f9/64
reth0 UP
reth1 UP
reth2 UP
reth3 UP
reth4 UP
reth5 UP
reth6 UP
reth7 UP
bond0 UP 200.18.0.14/30
bond1 UP 200.18.0.30/30
bond2 UP 200.18.0.46/30
bond3 UP 200.18.0.58/30
docker0 UP 172.17.0.1/16 fe80::42:3cff:fe24:242b/64
vethd5122f5@if18 UP fe80::3cad:ff:fe13:848d/64
测试得到NIC0(mlx5_bond_0)到各个GPU的带宽:
| GPU id | BW peak(Gbps) | BW average(Gbps) |
|---|---|---|
| 0 | 195.06 | 195.06 |
| 1 | 195.06 | 195.05 |
| 2 | 178.86 | 178.81 |
| 3 | 175.84 | 175.83 |
| 4 | 124.39 | 124.38 |
| 5 | 124.23 | 124.22 |
| 6 | 124.28 | 124.27 |
| 7 | 119.12 | 119.11 |
可以看到GPU1和NIC0的链路是PIX,带宽接近200Gbps的上限,为195.06Gbps。
GPU0 ↔ NIC0 被标为 NODE, 但这个 NODE 属于优质NODE ——CPU 内部互联(Ice Lake Mesh)足够宽 → 实测带宽接近 PIX。
其他 GPU (比如 GPU2/3) 虽然也是 NODE,但所在的 Root Complex 通道资源更有限 → 实测带宽低 10–15%。
2. RDMA
RDMA网络组成:
- 应用层:应用一般通过ibverbs api与RDMA网卡交互
- 传输层:寻址,RDMA 没有”IP 地址”和”MAC 地址”
- 网络层:
- InfiniBand:私有协议,比较贵
- RoCE(RDMA over Converged Ethernet)
- 数据链路层:网卡, 最常见的RDMA网卡是Mellanox的ConnectX系列网卡
| GPU型号 | 常见搭配网卡 | 网络速率(bps) | 发布时间 |
|---|---|---|---|
| V100 / T4 | ConnectX-4/5 | 25G / 50G / 100G | 2017–2018 |
| RTX 3090 | ConnectX-5 | 100G | 2020 |
| RTX 4090 | ConnectX-5/6 | 100G / 200G | 2022 |
| L40S / 6000 Ada | ConnectX-6 | 200G | 2023 |
| H20 | ConnectX-6/7 | 200G / 400G | 2023 |
| A100 | ConnectX-6 | 200G | 2020 |
| H100 | ConnectX-7 | 400G | 2022 |
| H200 | ConnectX-7/8 | 400G / 800G | 2024 |
| B200 | ConnectX-8 | 800G | 2024–2025 |
| Grace Hopper GH200 | ConnectX-7 | 400G | 2023 |
RDMA支持的操作:
- 双边RDMA,需要通信双方的CPU参与:
- RECV: 目标方准备接受消息
- SEND: 发起方将信息发送给目标方
- 单边RDMA,只需要发起方的 CPU 参与,目标方 CPU 并不知情
- WRITE: 将数据从发起方的内存直接写入目标方的内存
- WRITE_IMM: 类似 WRITE,将数据从发起方的内存直接写入目标方的内存,但额外地在目标方的完成队列(Completion Queue)中插入一个整数,用来通知目标方 CPU。
- READ:直接从目标方的内存读取数据并写入发起方的内存
- ATOMIC:对目标方的内存进行原子操作,如 Compare-and-Swap、Fetch-Add
— 来源:Chen Lequn 的博客
在 RDMA 中,一对通信节点被称为队列对(Queue Pair,QP)。类似于 IP 协议上常用的两种传输类型 TCP 和 UDP,RDMA 上有三种传输类型:
- 可靠连接队列对(Reliable Connected Queue Pair, RC QP)
- 基于连接,因此在通信之前需要先建立连接。通常来说连接数有限制。
- 可靠传输,包含重传,保证消息送达顺序。
- 可以一次性传输很大的消息,消息的大小可以远超 MTU。
- 支持所有 RDMA 操作:RECV、SEND、WRITE、READ、ATOMIC
- 不可靠连接队列对(Unreliable Connected Queue Pair, UC QP)
- 类似 RC,但是传输不可靠,不保证消息送达,不保证消息送达顺序。
- 只支持部分 RDMA 操作:RECV、SEND、WRITE
- 不可靠数据报队列对(Unreliable Datagram Queue Pair, UD QP)
- 无需建立连接。
- 不保证消息送达,不保证消息送达顺序。
- 消息必须小于 MTU
- 只支持 RECV、SEND
— 来源:Chen Lequn 的博客
推理系统里面为了可靠通信一般都用的RC QP。
3. 高性能网络系统设计哲学
见libfabric的intro,感觉关键点一个是要做到零拷贝,还有就是要尽量减少和内核的交互。
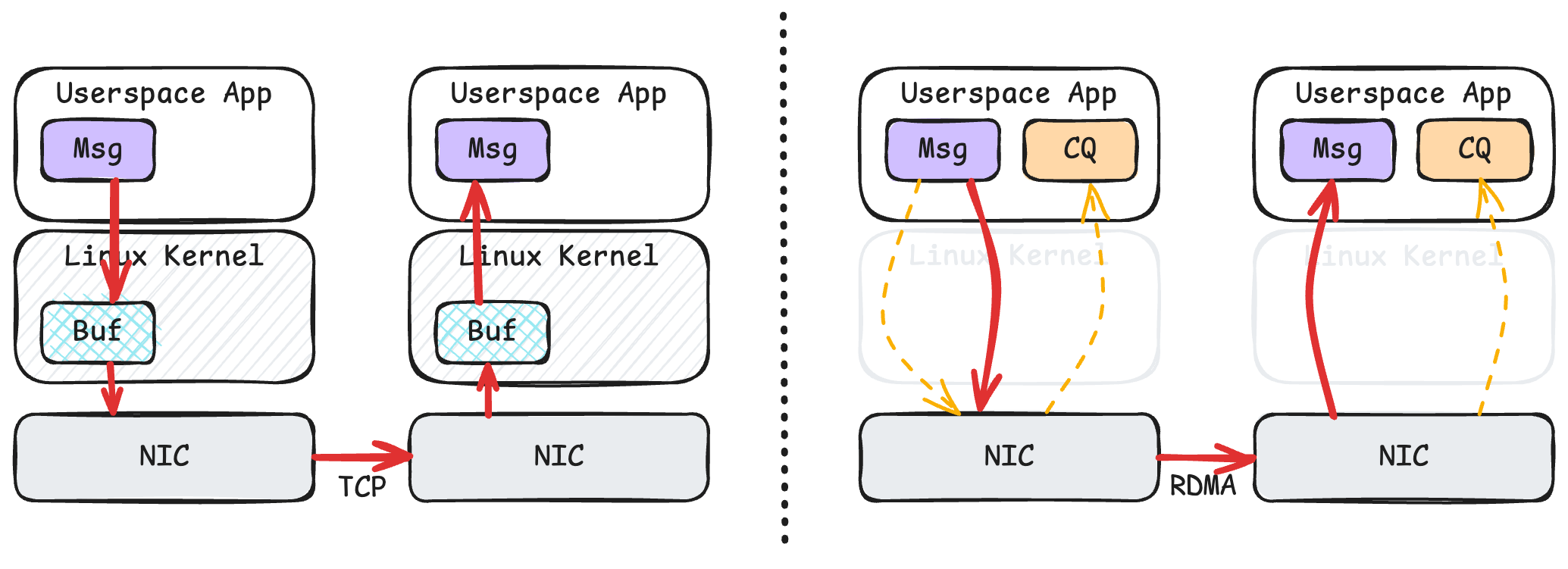
3.1 TCP和RDMA
socket接口设计为了易用性,需要将用户态中的应用数据拷贝到内核提供的缓冲区中,多出来的这一次拷贝会影响传输性能。
为了避免多出来的这一次拷贝,可以让应用和网卡共享一段内存缓冲区,在发送数据时,网卡可以直接从内存读取数据;在接收数据时,网卡可以直接将数据写入到内存中;应用程序可以轮询(Poll)网卡的完成队列(Completion Queue)来知道网络操作是否完成,而这个轮询操作只不过是读取某段虚拟地址而已。 — 来源:Chen Lequn 的博客
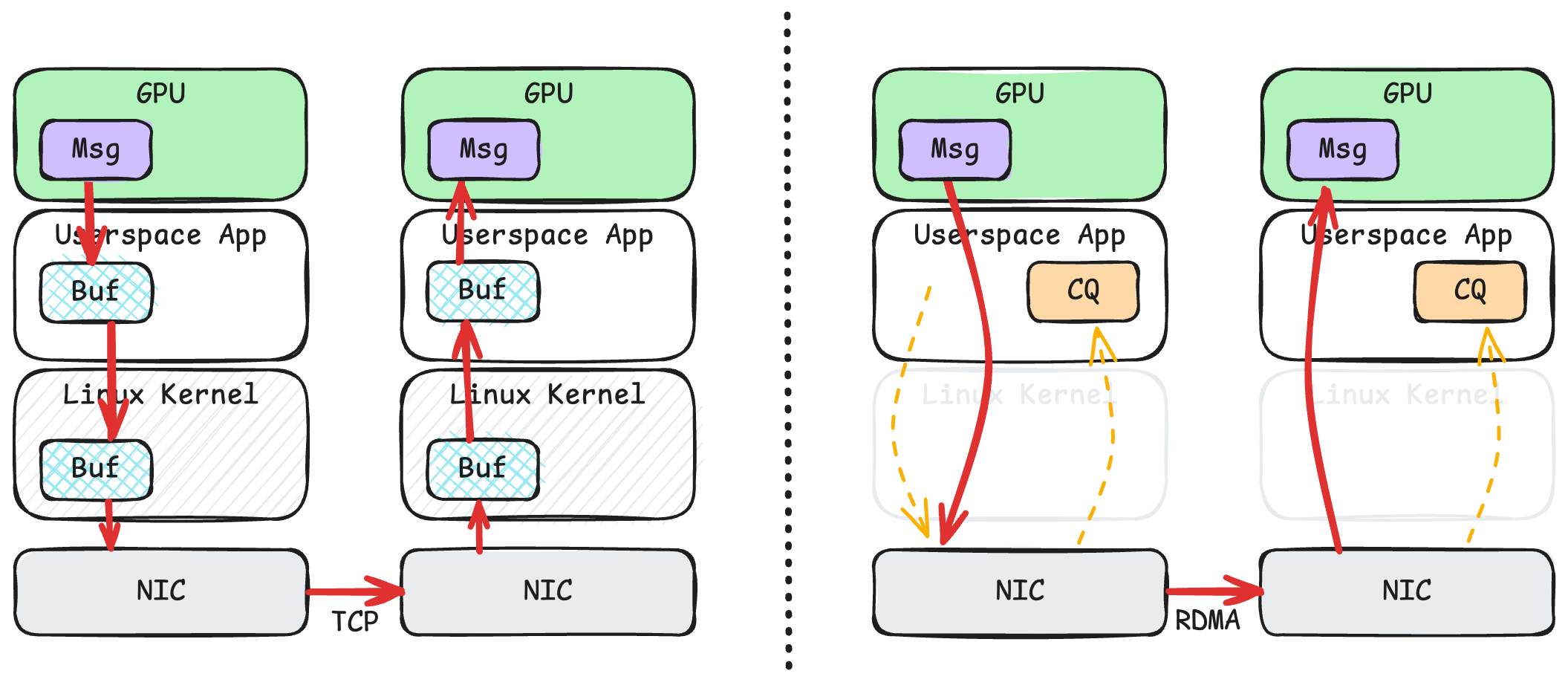
3.2 TCP和GPUDirect RDMA
GPUDirect RDMA:
当应用程序要发送数据的时候,用户态进程只需要告诉网卡这个消息所在的虚拟地址,网卡就能直接读取显存。值得注意的是,用户态进程在发送消息的时候,并不需要刻意区分到底这个虚拟地址是在 CPU 内存上的,还是在显卡的显存上的,因为内核已经提前设置好了 CPU、显卡以及网卡的页表,使得他们能够理解同一个虚拟地址空间。接收端也是类似的,网卡直接将数据写入显存,无需经过任何额外的复制。 — 来源:Chen Lequn 的博客
4. libfabric
libfabric是一个RDMA通信库,应用调用libfabric的上层接口,具体的通信协议由不同的provider实现,provider包括tcp、udp、shm(共享内存)、verbs(RDMA ibverbs)、efa。
- 为什么需要libfabric这样的通信库:NCCL、pytorch支持的集体通信(Collective Communication)需要建立全局的通信域,如果要动态地添加/删除通信节点(比如点对点传输kv cache),使用更上层的NCCL就需要先暂停整个集群的通信。
应用层 (MPI / NCCL / NVSHEMEM / ...)
|
RDMA verbs / libfabric (统一编程接口)
|
----------------------------------------
| |
InfiniBand RoCE (基于以太网)
(专用网络栈) (以太网封装)
|
Mellanox HCA (ConnectX-6/7, BlueField)
|
[可选优化: IBGDA = GPU 直接驱动 NIC 提交 RDMA 请求]
- IBGDA(InfiniBand Global Data Access):是 NVIDIA GPU + Mellanox NIC 协作的一种机制。传统 RDMA 时,GPU 发起的通信需要 CPU 参与(比如由 CPU 提交 Work Queue Entry 到 NIC)。开启 IBGDA 后,GPU 内核可以直接通过 doorbell / BAR 映射 向 NIC 提交 RDMA 请求,实现 GPU 驱动 NIC,CPU完全绕过。
软件对象模型:
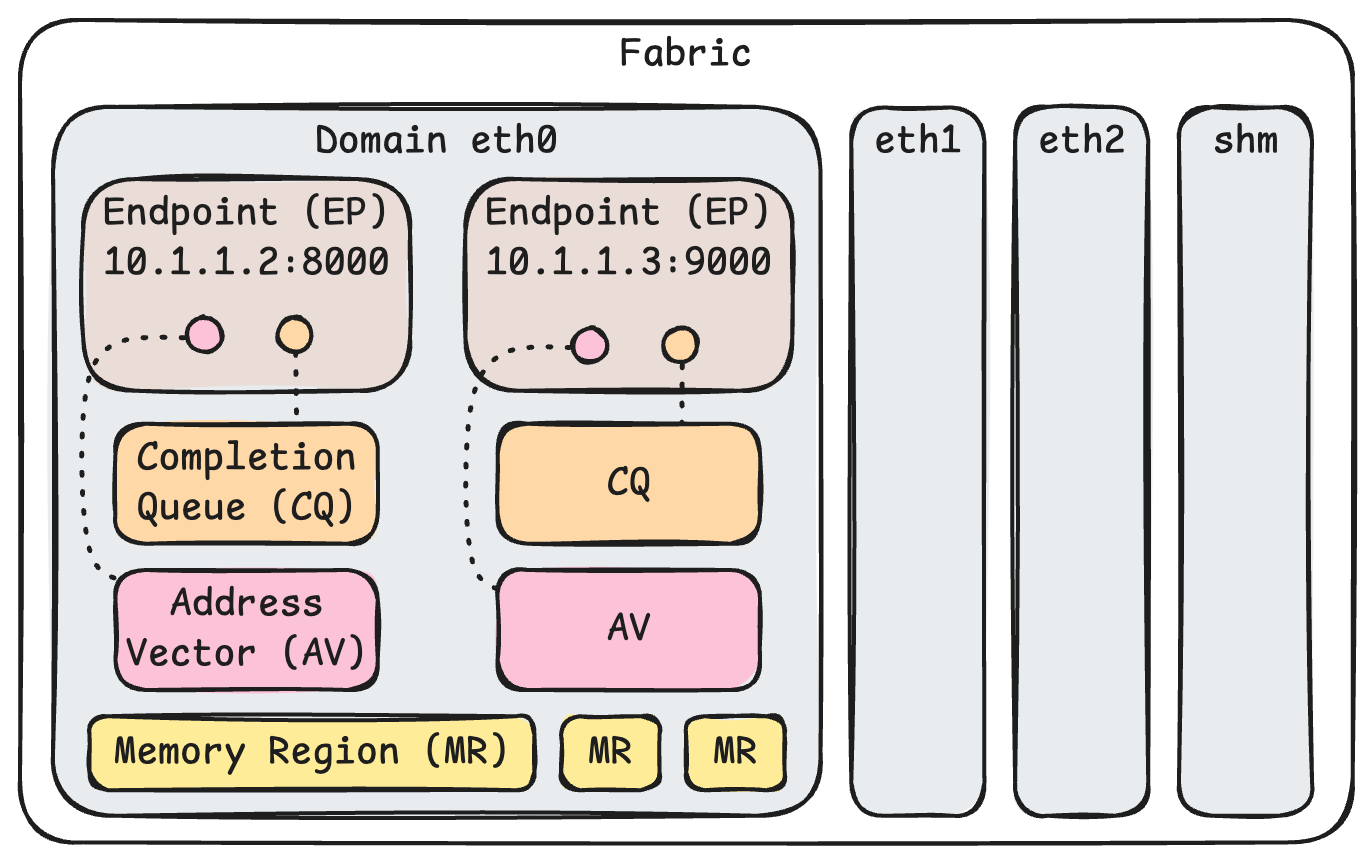
- Fabric: 所有硬件资源和软件状态的的集合,类似于用于保存全局状态的一个结构。
- Domain: 类似于一张网卡,例如 eth0。一个 Fabric 可以拥有多个 Domain。
- (EP) Endpoint: 数据收发的端点,一个 Domain 可以拥有多个端点,并且每个端点也有不同的类型。例如在同一张以太网卡上,可以监听多个 ip:port,可以使用 TCP 和 UDP 这样不同类型的协议。
- (EQ) Event Queue:事件队列,用来报告控制平面操作的完成。
- (CQ) Completion Queue: 完成队列,报告数据平面操作的完成(RECV / SEND / WRITE / READ)。CQ 属于 Domain,可以绑定到 Endpoint 上。
- (AV) Address Vector:存储解析过的网络地址。需要先将通信的另一方加入 AV 才能对其发起通信。AV 属于 Domain,可以绑定到 Endpoint 上。
- (MR) Memory Region:用于收发数据的缓冲区。无论是哪种 RDMA 操作,都需要指定 MR。注册 MR 需要经过操作系统内核,因为操作系统内核需要设置 CPU 页表以及其他 PCIe 设备的页表。 — 来源:Chen Lequn 的博客
5. NVSHMEM与NCCL (待补充)
6. DeepEP (待补充)
7. MoonCake与NIXL (待补充)
参考链接
- Chen Lequn博客:https://abcdabcd987.com/2024/12/25/libfabric-efa-0-intro/
- Libfabric高性能网络系统设计介绍:https://ofiwg.github.io/libfabric/v2.0.0/man/fi_intro.7.html